
My first accounting job is still fresh in my mind. I was 26, working in finance on complex calculations called capitalized variances. As part of the evaluation of a company’s inventory, capitalized variances take into account price changes in production materials. These calculations can get tricky due to timing offsets.
I was trembling the first time I calculated the figures. They were being sent directly to the CFO. I had to manage all these figures in Excel which was extremely stressful. Of all the accountants, analysts, and controllers who worked on consolidating the quarterly business results, it was my calculation that would have the biggest impact on Operating Income and Profitability for the quarter.
I remember thinking how unnecessary it all was. Why was I forced to be stressed when the calculation could easily have been automated? I inherited an unnecessarily complicated Excel spreadsheet for calculating the variances which was why usually only very Senior Financial Analysts were allowed to use them. Despite lacking the seniority, I was given the sheets to work with and felt terrified that I’d make a mistake.
After all, there were dead formulas in the file, date labels were wrong, and running simulations required changing data in multiple sheets. It was easy to get an incorrect estimate. At this moment I realized that new technology is the solution to making calculations faster, more transparent, and less error-prone, but it is only useful if it brings less complexity. Less complexity in technology is key and leveraging boring tech is the best way to ensure it.
To remove unnecessary complexity, I took the following steps:
- I began by cleaning up the data
- I then moved to the data models, making the modeling logic transparent and straightforward
- The final step was to use plain Excel
Though I was tempted to add VBA macros (or better yet, Python) to automate processes, I knew my successors might not have any experience with VBA and probably wouldn’t be able to understand my “cooler tech.”
The result was that capitalized variance became easy enough that I could eventually hand over the spreadsheet to more junior people. I managed to significantly reduce the complexity while increasing my job satisfaction.
To Scale, Make Things Easier… with Boring Tech
Whether scaling an organization or improving an organizational process, removing unnecessary complexity is the priority. “Boring tech” might seem a bit vague, but it refers to software that has been around for a long time and is widely understood.
Only after adopting boring tech and maturing your digital organization should you consider employing more complex technologies – and only once it becomes absolutely necessary and has a clear purpose.
Boring tech helps us answer a key question:
How can I make my work easier and more efficient?
By avoiding impractical, unnecessary tech, you can make your work easier and more efficient. Fancy new features never outweigh sustainability solutions.
SQL databases are examples of boring tech because they have been around for a few decades now. Most data professionals know how to work with them, and they are battle-tested.
Kubernetes, on the other hand, is not boring tech because it has not been in use for long enough. It can add value for DevOps, but it is also not widely used or accepted by data professionals. This means that maintaining it is challenging, adding significant complexity to data operations. Nevertheless, Kubernetes can be made into boring tech! If we standardize it, support an uncomplicated deployment system, and remove unnecessary complexity from it, then it can become operated by a less skilled worker.
Knowns and Unknowns of Boring Tech
Luca Rossi says that any technology has upsides and downsides. Paraphrasing these into the knowns and unknowns framework, we have:
- Known wins — things we know it is good at
- Known failures — things we know it is bad at
- Unknown failures — things it is bad at, but we still don’t know
By his definition, boring tech has almost everything figured out:
- Many known wins — it is widely adopted and supported
- Many known fails — limitations are well-known and documented
- Few unknown fails — we know it inside out because so many things have already been tried
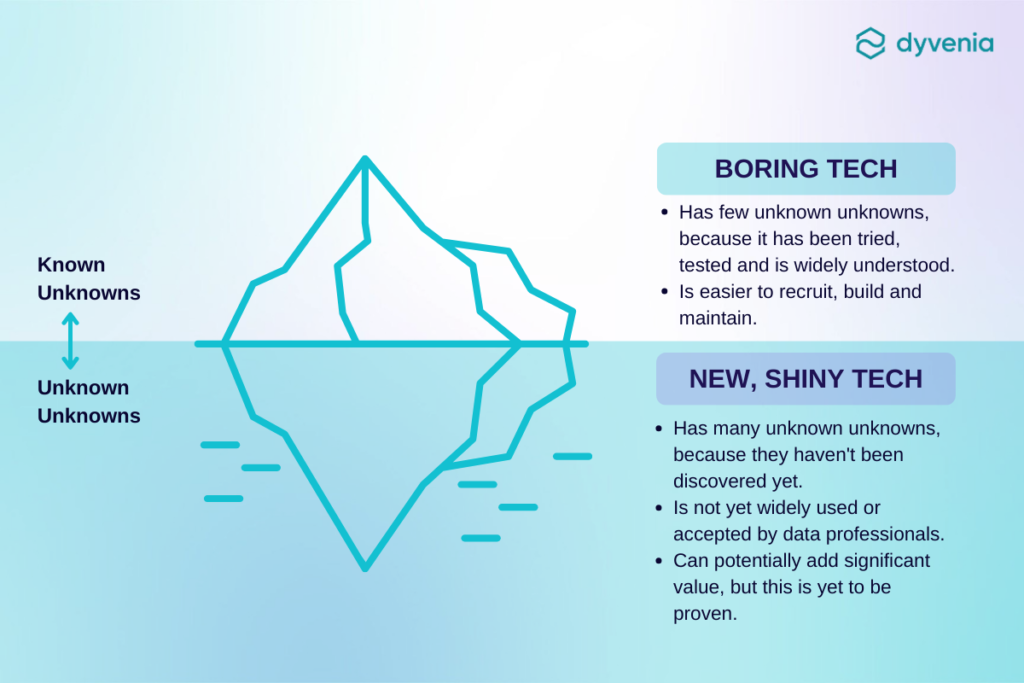
New tech has many unknowns, while boring tech has been tested and is widely understood.
Boring Tech Widespread
Boring tech is so widespread that new tech often tries to be compatible with it.
One of the easiest ways to migrate your data analytics solutions to the Cloud is to combine a data lake with SQL. This way, you can scale to petabytes of data using new tech while still making your data available to people using good old SQL.
If I had to guess, I’d say that 80% of analytics today is still done in SQL. SQL was invented in the 1970s, and it is an old but established way of querying and manipulating data. Data professionals from many career paths know SQL, and those who don’t can learn it in a few weeks.
You can also do a lot with more straightforward statistical tools. These tools are well-suited to programming languages like R or Python. They have been around for a while, and their real-world usage for many years has hardened them.
Boring Tech is the Best Way to Mitigate the Talent Shortage
One of the most significant advantages of using boring tech is that it allows you to leverage a vast talent pool with technical and domain knowledge.
There are two big reasons why boring tech tends to have a wider pool of talent:
- They’ve been around longer, so people have had more time to figure them out.
- They are extremely simple, so people can quickly learn how to use them.
A better way to pick technology is to examine the type of talent you already have within your company as well as the type you and your company can attract from the job market. It’s a challenging exercise because every company wants to be as cool as, say, Google or Apple, but these companies have very different data challenges than most.
But it Doesn’t Scale!
You can scale a single database instance to a few terabytes and thousands of users, but is it ideal? Sometimes yes, sometimes not. You should choose what is best for your situation, not what the masses are promoting at the moment. What’s critical is to catalog and manage the data exceptionally well. Think of yourself as a librarian – data doesn’t change as fast as technology does.
Tech will continue to evolve, but solid, boring tech will remain foundational. SQL is here to stay; the same goes for many programming languages. Many other UI-based technologies will continue to evolve, which is fine as long as you develop with them.
Remember that before Cloud, there was Big Data and Hadoop. Hadoop was a revolutionary set of tools that allowed companies to analyze increasingly big datasets. However, Hadoop was complex, so several startups were created to simplify it, including Cloudera. If your company went into data science before 2016-2017, it might have had Hadoop on-premise and a vendor like Cloudera. However, the world moved on in just a few years, and Hadoop on-premises lost its position as the gold standard. Instead, running on the Cloud exclusively became number one. If your company was on Hadoop/Cloudera, you might have been forced to migrate to another technology after just five years. But here is the good news: your underlying data probably hasn’t changed! Your company has probably been using the same data structures for decades.
Remember: data is like glaciers, it changes very slowly.
OK then, when Can I Use the New Tech?
I find it very difficult to keep up with all the new technology developments and to estimate if/when this new piece of tech is worth a try. I try to use the new sparingly and prudently. Even though I have a whole team at dyvenia constantly working on new tools and technologies, we still go for boring tech whenever possible.
Before adopting new technologies, I want to prove its value first. As in my capitalized variance story, many times value can be added by removing complexity from existing tools and processes first.
Another way to introduce new tech is to test it first on a few non-critical projects. That way the organization can start digesting the “new” parts of the technology.
New technologies should be adopted carefully, over time, with a plan and very strong communication around values and processes. The goal here is to minimize the chances of failure and increase the chances of success. This requires a different mindset – not adopting new tech and expecting excellent results, but adopting it, accepting risks, and preparing for potential unknown failures.
Conclusion
Businesses undervalue boring technology. Usually, their goal is to incorporate the latest technologies into their company’s systems. Unfortunately, it is often done haphazardly, and too little consideration is given to the benefits of boring technology. Businesses using established technologies are more profitable because they are easier to recruit, build, and maintain.
I highly recommend using a boring technology stack. You’re in the business of resolving customer issues. It doesn’t matter what technology you use. Instead, focus on satisfying your customers and benefit from the speed and scalability that boring tech brings.
This article was originally published by dyvenia CEO Alessio Civitillo on his LinkedIn page.


