

The Changing Data Landscape: Adapting with Metadata Management and Automation
Currently, businesses generate approximately two billion gigabytes of data daily. This growth in data creates a huge demand for skilled professionals and emphasizes the need for a reliable, unified view of an enterprise’s data assets. On top of managing this data tsunami, companies make every effort to comply with government regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA).
To tackle the challenges of this uncontrolled growth of data, talent shortages, and an uncertain regulatory landscape, many businesses look to automation. But here’s the catch—the continuous influx of AI-driven technologies triggers a strong fear of missing out. Consequently, some companies end up adopting solutions that don’t quite fit their specific needs and structures. So, how can you stay cautious and leverage automation without losing sight of what matters most to your organization?
This article sheds light on the potential of metadata management as a strategy to solve this dilemma. We will guide you in finding the right solution to navigate this complex landscape, satisfy regulatory demands, and make informed decisions that move your business forward.
Let’s dive in.
Top Five Key Concerns Of Data Leaders
Despite vast data access, many organizations struggle to fully leverage its potential. What hinders them from maximizing data value?
Challenge #1: Multiple Data Silos with Limited Collaboration
Siloed data is a frequent friction point in larger companies where business units operate independently and manage their own data. This creates isolated data repositories owned exclusively by specific teams within the organization while remaining inaccessible to others. The result? Other teams lack visibility into these data silos, leading to collaboration issues and team barriers.
Challenge #2: Poor Data Quality
Managing data from numerous sources poses a significant challenge for organizations, as it becomes difficult to maintain accuracy and reliability. In fact, about 91% of CRM data remains incomplete, and roughly 70% of that data becomes inaccurate each year. This often diminishes data trust, which hinders its use and prevents organizations from achieving their strategic goals.
Challenge #3: Slowness and Manual Practices
Despite the growing importance of automated solutions, manual processes still persist as a common approach. According to IDC, a staggering 80% of data practitioners’ time is dedicated to managing, searching, preparing, and protecting data, leaving less than 20% for actual analysis and value extraction. This results in redundant workloads and significantly slower time to market.
Challenge #4: Lack of Data Control
Because of the growth in collecting and storing personal or sensitive data, organizations have become more vulnerable to security breaches and legal issues, particularly under regulations like GDPR and CCPA. Without effective access control and a data governance plan in place, ensuring the proper handling, processing, storage, and use of personal information becomes an overwhelming challenge.
Challenge #5: Lack of Knowledge and Skills
The increasing reliance on data results in a growing demand for data professionals. According to the U.S. Bureau of Labor Statistics, the number of jobs requiring data science skills will increase by nearly 28% by 2026. However, finding qualified experts is challenging, and training entry-level staff takes time, especially for companies dealing with new technologies. The consequence? Slower insights generation, subpar analyses, missed opportunities, and elevated costs.
What Is Metadata Management?
Simply put, metadata is ‘data about data’. It provides insights about the data’s origin, format, quality, and any modifications made. Common examples of metadata are file size, image characteristics, date, authorship, and keywords. Understanding metadata is crucial for analyzing and determining your data’s utility.
Metadata management can be defined as a strategy to manage the collection, storage, and use of metadata. Its goal is to ensure the metadata is well-organized and easy to find so that anyone needing specific data can quickly locate it.
By managing metadata effectively, you can easily answer important questions about your data, such as:
- Can I use this data? Is it correct?
- Is this data compliant with company policies?
- How can I access this data?
- Is this data current or obsolete?
- How was this data modeled? What is the lineage?
- Who owns this data?
Answering these questions through metadata management ensures high-quality, policy-compliant, easily accessible, up-to-date, well-understood, and efficiently used data.
Key Benefits Of Automated Metadata Management
Automation of metadata management can have several benefits:
Improved Consistency and Collaboration
Establishing a centralized repository provides a unified data view across various departments and systems, promoting seamless collaboration. They can now communicate and work with a shared understanding of the information.
Increased Data Quality
The automated approach identifies data issues fast, ensuring data accuracy, and reliability. High-quality data leads to trustworthy insights, driving informed business decisions.
Faster Access to Insights
Clear metadata definitions and relationships enable users to quickly locate and understand relevant data, reducing time spent on data exploration and fostering fast and informed decision-making.
Data Standardization and Regulatory Compliance
Metadata management enforces data standardization, playing a vital role in meeting regulatory compliance requirements, such as GDPR, CCPA, and other data protection laws. By automatically tagging sensitive data and documenting its lineage, organizations can demonstrate transparency and accountability in how data is collected, processed, and used.
Effective Implementation Of Metadata Management: Four Best Practices
While every organization must tailor its metadata management strategy to its unique needs, the following best practices can optimize metadata management:
Best Practice #1: Automate Metadata Ingestion from Data Pipelines
This reduces manual work and human errors, leading to significant time savings, improved metadata quality and consistency.
Best Practice #2: Implement Automated Quality Assurance
Real-time insights into metadata quality empower data producers (e.g., data engineers) and data consumers (e.g., data analysts) to operate efficiently while minimizing the need for generating tickets or seeking external assistance.
Best Practice #3: Include Diverse Sources and Data Pipeline Tools
This ensures comprehensive metadata ingestion, incorporating all relevant data streams into the management system.
Best Practice #4: Unify Stakeholders in a Centralized Data Catalog User Interface
Bringing metadata consumers, producers, and business users together in one place through a unified data catalog fosters collaboration and enables seamless data understanding and usage across the organization.
Exploring Automation in Metadata Management: Insights from luma Data Catalog
As we’ve explored, automation lies at the heart of effective metadata management, and a robust tool can assist in this process. Our solution, the luma data catalog, has been designed with the specific purpose of automating the collection of metadata from data pipelines, lakes, and warehouses.
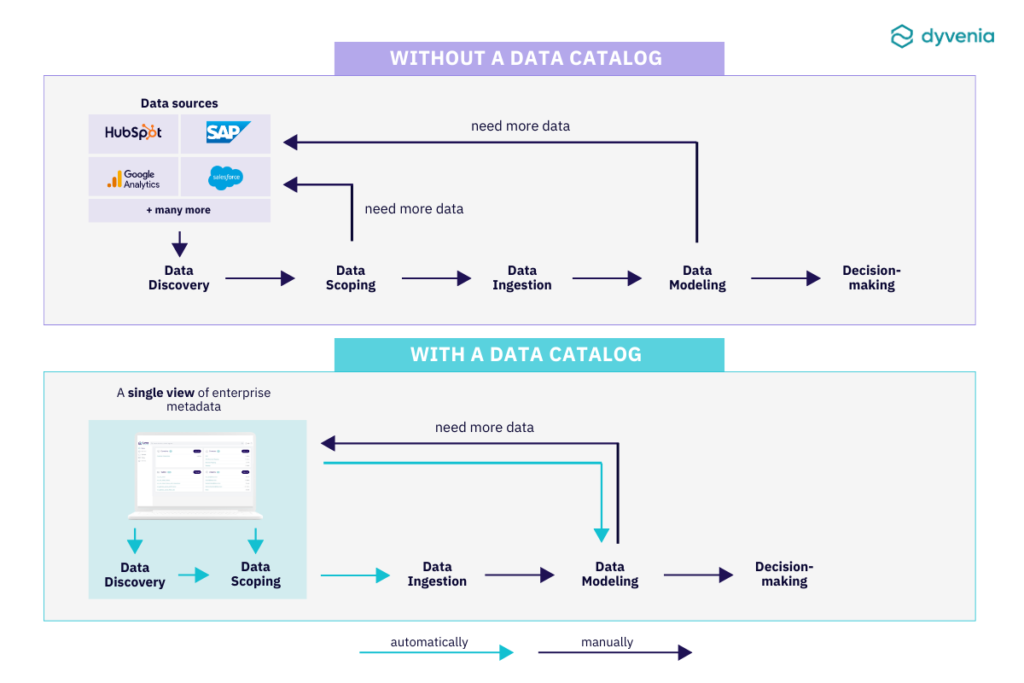
Managing metadata without a data catalog is possible, but it poses significant challenges for data leaders in today’s data-driven environments. Without a catalog, it becomes a manual and fragmented process, resulting in inefficiencies and difficulties in accessing and using data effectively.
In addition to automation, luma has several capabilities beneficial for large organizations:
- Addressing Data Silos. luma’s platform is centralized, allowing data from various sources to be indexed, organized, and easily found by users. This eliminates the isolation of data in separate silos and encourages data sharing and collaboration within an organization.
- Enhancing Data Quality. luma’s data profiling capabilities help identify inconsistencies, errors, and redundancies. By addressing these issues, data leaders can implement data quality improvement strategies and ensure that data remains reliable and fit for its intended purposes.
- Improving Data Control. luma allows for proper data classification, tagging, and documentation, ensuring clear ownership and accountability for data assets. With a centralized platform for managing metadata, data leaders can easily enforce data governance policies.
- Mitigating Talent Shortages. luma provides a user-friendly interface that simplifies the process of discovering and understanding data assets, reducing the dependency on a few specialized data experts. Moreover, it facilitates collaboration and knowledge sharing among teams, while optimizing the use of existing data talent and accelerating the onboarding process for new members.
To understand more about the possible benefits of tools like our luma Data Catalog in your metadata management, contact our team of experts for a personalized demonstration today. You can book an obligation-free call here.


